
 Login/Register
Login/Register Supplier Login
Supplier Login









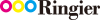
















 The 3-step system for the paper check
The 3-step system for the paper check
Step 1 - Screening (≈ 5 min)
Skim abstract, LinkedIn post or hugging face-readme
- Alarm bells: Huge “SOTA jumps” without clear justification
- Discrepancy with the research consensus
- Lack of code or data
Stage 2 - Validate (≈ 15 min)
Figures + experiments + related work of a follow-up paper
- Does the paper really compare its method fairly?
- Have independent authors confirmed the results?
- Does the data set match my own?
Stage 3 - In-depth (1-2 h)
Study core chapter, roughly execute code
- How clean is the implementation?
- Are hyperparameters properly documented?
- Can I integrate this into my pipeline (MLOps)?
Only those who pass stage 3 end up in Tom's roadmap.
Tom uses the following tools:
- Perplexity AI (with ArXiv filter): Search queries in natural language, finds papers far away from Google page 1
- ChatGPT / Notebook LM: Get explanations, generate quiz questions, answers always with sources
- auto-sklearn: Quickly generate baseline models and discover weak points in the data set
- YouTube: Visual deep dives or beginner explanations
- Reddit r/MachineLearning: Early warning system for brand new models, repos and leaks